Technology Roadmap: Rewrite vs Refactor
Article
We are living through an era of increasing innovation and incredible investment in start-ups of all industries. It’s a profound time to be a technologist and entrepreneur. It’s also incredibly competitive and if you and your technology can’t move nimbly, your business will likely sink.
Success through technology
While industries everywhere are exploring how to tap into new markets or expand existing ones.. the technology and its implementation are critical to allowing a business to experiment and make fast decisions on direction. Getting bogged down in a tech stack that is difficult to perform experiments with is not an option and will lead to competitors putting you out of business.
What I’ve Found
I’ve spent the last 5 years working with start-ups of all sizes. It was imperative for every one of these to have the technical agility to experiment with an opportunity, tweak it, note results, and repeat. Many are able to do this.. but many more are not.
Start-ups that do move fast
Are typically just starting out. If you’re building from scratch.. you don’t have a whole lot slowing you down.
Start-ups that move slow
It is unfortunate, but every start-up I’ve encountered and worked with that was more than 3 years old, had some form serious technical challenges impeding their speed. They were unable to capitalize on many or most opportunities presented to them. This is a recipe for failure.
The golden goose
It does happen that a start-up has both moved quickly in the early stages and continued to expand its technology through that growth without resulting in crippling technical debt. It’s rare though.
Go from slow to fast
This article is not going to focus on how you achieve an agile, maintainable, expandable technical stack from day one and keep it through year five and beyond (though I’ve executed on teams achieving this, it is possible).
Instead, we’re going to look at how a business and their tech stack can move from a crippling slow speed of engineering to one where your technology is able to facilitate business exploration and growth with ease. I’ve seen it done. It doesn’t happen overnight, involves significant trade-offs.. and can be a myriad of combined strategies.
First: Analyze & Strategize
We’re talking about the scenario where a business has gradually found the flexibility of their tech stack decreasing and they’ve reached the point of ‘Ok, we’re ready to do something about this: shift things and make compromises to increase flexibility for business capacity or expansion.’
Understand the picture
Look at the entire tech stack. Where are things slow, why? What are the critical areas that if improved, would allow for the most exploration of the product?
Metrics are key and we’ll dig into those later. Gather metrics about where time is being spent and talk to engineers about what are the most painful areas of their day-to-day work.
The Big Decision: Refactor vs Rewrite
Refactoring can actually be expensive & risky.
The concept of refactoring is now a prevalent one. And rightly so. It’s a powerful tool in the toolbox for keeping code clean & consistent. It’s also a learned practice and becomes increasingly challenging to do well when dealing with a particularly messy/complex codebase.
In cases where the components slowing down engineering are large, messy, complicated and inconsistent codebases, it can actually be more expensive and risky to take on a refactor only strategy.
Engineers performing the refactoring need to:
- Understand the current codebase (which may or may not have a describable ‘architecture’).
- Understand the ideal or new architecture.
- Be able to take the slow intermediary steps to move from the current to the new.
The idea of refactoring is easier for a business to deal with. Often, you’ll see teams come up with a strategy of specifying how much time will be spent on refactoring. ‘We’ll spend 20% of our time on refactoring.’
The issue with this is that it’s not a valuable metric for how much enablement the tech is providing to business exploration and success. This team could be spending 20% of its time on refactoring and still be squeaking forward with new features or capabilities for the product and its users.
Evaluating a Rewrite
A codebase rewrite is a difficult pill for a business to swallow. The idea of throwing away code that a lot of resources have been invested in is tough and feels wasteful. There’s also the likelihood that there will be a longer wait for those new exciting features while the current functionality is re-examined and re-implemented.
Deciding
Gather metrics.
- How much actual time is being spent on new feature work.
- How much time is being spent on regression (bugs).
- How much time is being spent refactoring.
How experienced is the team?
- Have team members done significant refactorings or rewrites before.
- For either path you need a proportion of team members to be architecturally guiding members. Architecture should be decided by the team, but it’s imperative to have one or several members who’ve got the technical chops and the ability to guide the team towards a desired, efficient, flexible architecture. For the refactoring path, you need more of these types of team members involved in day-to-day coding as it’s a more complex journey.
- What is the team churn? Has anyone been around long enough to deeply know the existing architecture and all its inconsistencies. If not, these will continue to slow the team down as they are discovered.
How bad is the code?
- Get the team talking. What changes would need to be made to make things more navigable? How big are those changes. How risky are those changes? Likelihood of bugs and regressions when they happen. Could they happen slowly over a series of features and what would be the unknowns for that journey?
- Analyze those gathered metrics. If regressions and bugs are frequent and dominate team focus, that’s a red flag. You could be continuing to see that spread
What metrics can tell you.
At the center of this effort is often the realization that too much time is sunk into each new feature.
Ideal feature development in terms of effort spent on each stage of development should look something like this.
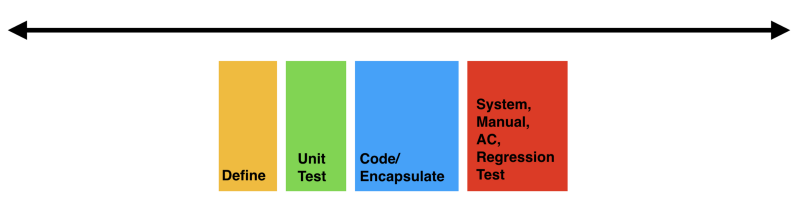
In a situation where perhaps just a targeting refactoring strategy might apply, your relative effort may look like this.
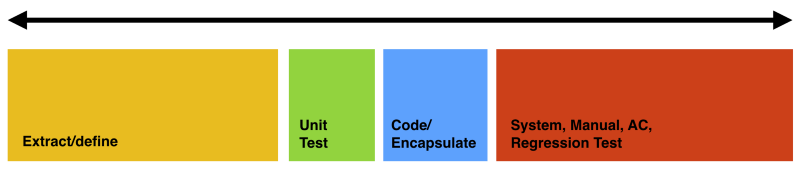
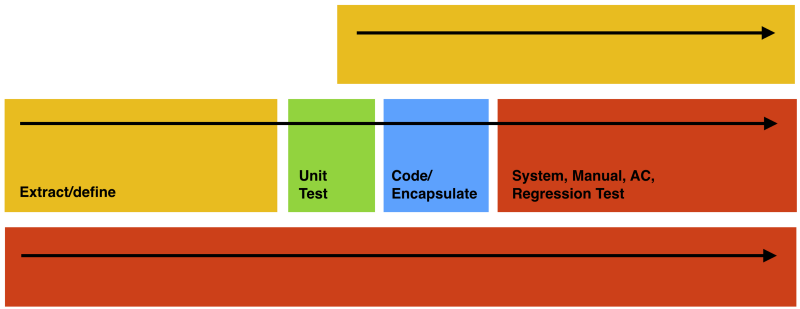
In a situation where it’s perhaps going to be more expensive to refactor than rewrite, your relative effort could be more like this.
Know the Risks
Any new shift in strategy carries risk. Evaluating risk from the outset is critical in minimizing waste and arriving at the new improved architecture that will propel your business forward. These are the top risks to keep in mind:
Lack of Metrics
Take the time to setup accurate tracking here. It will allow you to reach the right decision in strategy and provide visibility into whether your efforts are delivering more business value later on.
Lack of seasoned engineers who’ve walked the path before
Be it a long term refactoring strategy or a complete greenfield rewrite, it’s imperative to have a diverse team of talent. It’s ideal to have engineers who’ve undertaken the path you’ve chosen. Having this will significantly increase the likelihood of ending up with a clean, consistent, improved architecture at the end of your efforts.
Lacking of full buy-in from all stakeholders
From the product manager, UX designer, all the way to the CEO.. what’s going to spell the most success is involvement from all and visibility to all in the decision and progress in the rollout of that decision.
Summing it up
This article started out by introducing the idea that for start-ups to succeed, they must be able to experiment quickly in new potential areas of serving their customers.
If they happen to be hindered with a shoddy tech stack that makes this kind of experimentation extremely expensive, they are likely headed for failure (without some sort of course correction).
The options available are many, but span some form of refactor or rewrite. And this decision could be different across all parts of the tech stack causing problems. You may selectively choose to rewrite a portion and refactor a portion. Perhaps rewrite your APIs, but refactor your clients. It all depends.
Many time, however, a rewrite is not tackled as it is deemed to expensive in the short term. You often have to spend resources not only to build out the new, but maintain the old.
What’s at the root of the argument put forward in this article is that it’s often quite a bit more expensive and risky to refactor an inefficient and difficult to manage codebase. It takes the right technical leadership and team. And if you happen to have the team who are capable of this, you may spend more time still taking the codebase to the place where that fast-paced experimentation is possible.